How to get event logs for process mining
Process mining requires an event log
Process mining is a rapidly growing field. It’s where data science meets process management.
Process mining tools are maturing and are being incorporated into a number of leading business intelligence, automation, and process management tools.
While each tool offers slightly differing functionality, the core functions of process discovery, conformance checking, and performance analysis are available in whichever tool you choose.
The single requirement for any process mining tool is an event log. This always consists of a case ID, an activity name, and a timestamp. You can (and should) add additional data about each activity, which enriches your analysis.
An event log is created from system data and business information
An event log is rarely – if ever – available as a simple, one-click export from your information systems. (Despite what your IT team might tell you. They often think you’re just asking for system logs.)
You will first have to define your process, identify activities within that process, determine which of your IT systems holds a trace of that activity, then locate and extract the database table(s) that record the activity.
You will often need to locate and extract data separately for each activity in the target process. This is sometimes a complex task when the case ID – the identifier for the ‘thing’ traversing the process; an order, a customer, a support ticket – is not common across the systems you use in an end-to-end process.
For example, different IT systems used by a retailer may use different identifiers for the same order as the order is taken on a website, passed to a warehouse, then onto a shipment company. You will need to find bridging information to link this data.
Compiling a log for each activity is just the starting point. For an insight-rich process mining analysis, you should also add additional business data to this record of activities. Useful supplementary information could include:
- Resource data
- Location of the activity
- Team that completed the activity
- Cost of the activity (fixed and variable)
This cannot simply be the task of a data engineer working in isolation. A process expert and, ideally, a process improvement specialist should also be involved in creating an event log. This is because subjective decisions will inevitably have to be made and the perspective of all these stakeholders should be considered to ensure the analysis is focused on improving the process.
For example, without the input of the process expert, a data engineer can’t know what level of detail within an activity is appropriate for the process analysis at hand. ‘Account created’ could be the activity the process expert is interested in, not what the data engineer sees in the system database (e.g. ‘username created’, ‘password created’, ‘address set’, ‘phone number added’, ‘security questions set’, etc.) That would degrade the quality of the process mining analysis as the unnecessary detail could confuse the end-user and distract from your key message. These need to be grouped into a more meaningful ‘event’ and a decision made on which timestamp is most relevant.
A data model is how system data is converted into an event log
Developing the data model that generates the event log from the system data is the most important step in a process mining project.
Why? Because the eventual process analysis will have to be entirely defensible to the (often sceptical) stakeholders who will be asked to confront the findings of your analysis.
You will need to answer any and all questions on the dataset and the best preparation for this inevitable discussion around the robustness of the analysis is a carefully considered and well-documented data model.
Consequently, the data model that generates your event log should be easy to understand, easy to replicate, and easy to update.
Your data model is crucial: And should be constantly updated and augmented
Many of the process mining vendors seem to under emphasise the importance of the data model that generates an event log.
The suggestion is that you can ‘set it and forget it’, which isn’t correct. Your data model should be under constant scrutiny; how can it be improved? What additional data should be added? Is the activity scope too broad or too narrow?
There is no ‘correct’ answer to these questions and the needs of the business – as well as its process mining maturity – will constantly shift.
You should therefore see your data model as constantly evolving, iteratively improving, even over the course of a short process mining project. It may be useful to view the data model as a ‘product’ to be managed: In the first instance it will be an MVP that generates a rough-and-ready event log. Over time, more system data is added, more business information incorporated, the full end-to-end process captured.
Create your event log data model collaboratively
If your business is undertaking a process mining project for the first time and attempting to build a process mining capability, I would recommend spending more time than you think on the data model. Perhaps up to 80% of the time you have available.
It is tempting to rush to build dashboards to demonstrate the value of process mining, but the more time you spend on creating a quality event log, the more insightful and valuable your analysis will be.
If you are familiar with SQL and Python, it may be tempting to code your data model quickly and get an event log into a process mining tool as soon as possible. However, this hides the logic driving the event log dataset from stakeholders. Those stakeholders (i.e. business people who will be asked to implement change based on your findings, which is always painful) will need extremely high trust in how the data was compiled.
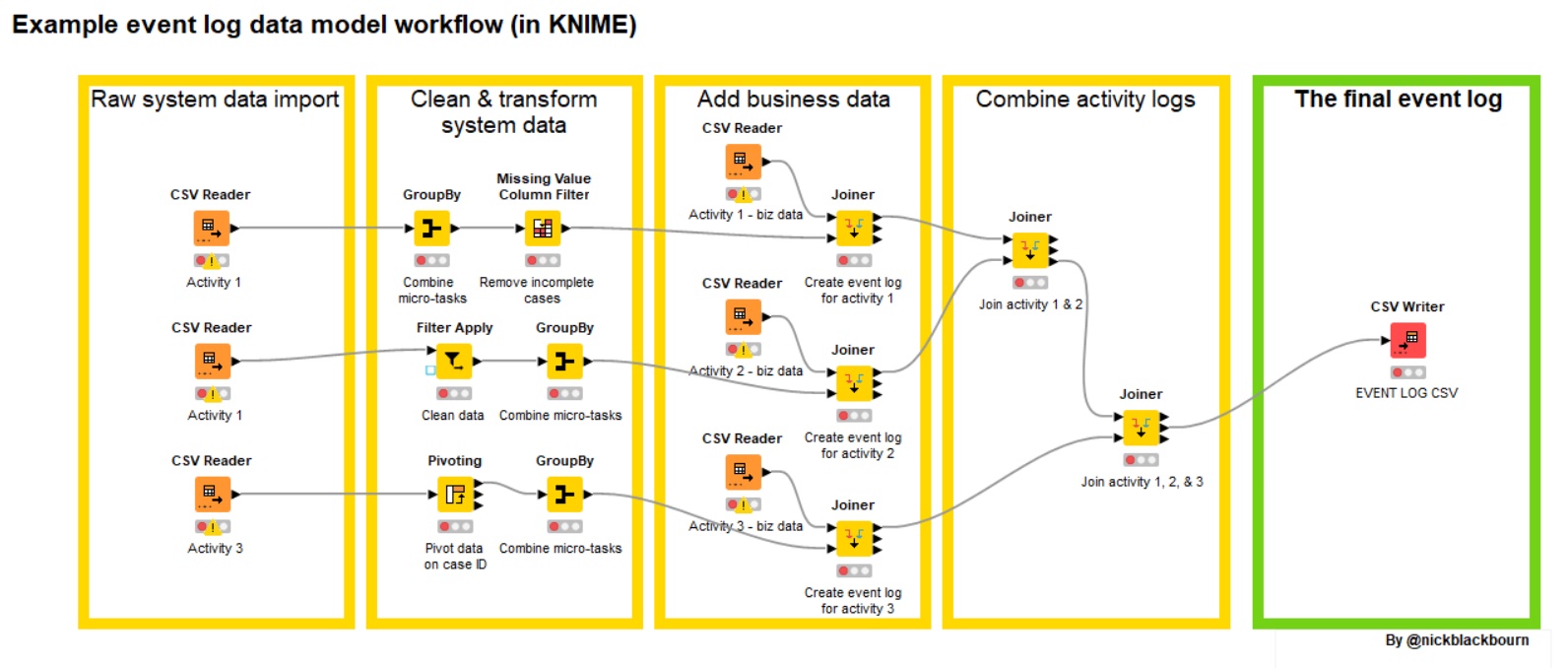
KNIME is an open-source analytics platform. It is a very visual tool and allows you to communicate your data model to non-technical stakeholders. It uses graphical elements to indicate different technical functions, and it is therefore easy to follow what is happening in the data model.
Tools like KNIME are an excellent way to achieve the transparency your stakeholders will require. It fulfils all the criteria mentioned above: easy to understand, easy to replicate, easy to update.
You can share your data model with nontechnical people who can follow the logic in your model as KNIME visualises data processing, allows for task grouping and has extensive annotation features.
This makes your event logs easier to improve iteratively, ensures confidence in your data, and, therefore, in the eventual findings of your process analysis.
Resources to learn how to create an event log
In this section, there are links to courses, books, and other media that will help you understand what event logs are and how you can make them yourself.
Process mining 101: Where to get the basics about process mining
[MOOC] From Theory to Execution – Will Van Der Aalst / Celonis
[BOOK] Successful Process Improvement: A Practice-Based Method To Embed Process Mining In Enterprises – Erik-Jan van der Linden
Event logs 101: Where to get the basics of compiling event logs
[VIDEO] Process Mining Cafe 6 ‘Sequences of Stuff’ – Anne Rozinat / Fluxicon
[VIDEO] Process Mining Cafe 4 ‘Mining Legacy Systems’ – Anne Rozinat / Fluxicon
[VIDEO] A Data Science to Process Mining ETL – Gerry Baird
[MOOC] IBM Process Mining: Data Analyst – IBM
[MOOC] Celonis Implementation Professional – Celonis
Data science 101: Where to get the basics of the data science methods you need to compile event logs
[MOOC] Databases and SQL for Data Science with Python – IBM
[MOOC] Data Analysis with Python – IBM
[MOOC] KNIME Analytics Platform for Data Wranglers: Basics – KNIME
[MOOC] KNIME Analytics Platform for Data Scientists: Advanced – KNIME
Process improvement 101: Where to get the basics of process improvement methods
[MOOC] Process Improvement – University of Illinois
[MOOC] Six Sigma Yellow Belt – University System of Georgia
On a personal level, the interdisciplinary nature of process mining is what draws me to the field. To make the most of process mining, you need a grounding in both data science and process improvement. This means there’s a lot of potential to learn new things and improve your organisation’s process mining capabilities in unexpected and interesting ways.
Where to go for event log generation help
Every business uses different systems and executes processes differently. While this does make life complicated for the process miner, it actually means there’s no reason for businesses to ‘hoard knowledge’ around their process mining techniques (even if they don’t share their actual process data). It’s unlikely to directly help the competition.
Process mining is therefore a hugely collaborative discipline.
So keep learning and keep sharing your experiences with process mining. This is a rapidly developing and maturing field and there’s plenty we can learn from each other.
In that vein, please reach out to me if you have any thoughts or questions on creating event logs, or if you’d like to read another article on something more specific, or just to say hello.
Also, if you need help building out a process mining capability at your own organisation, I work with a bunch of smart people at Capgemini Invent UK who would like nothing more than to sit down and talk through what it takes to do process mining well. We don’t have a tool to sell. Our goal is aligned with yours: to help you improve your processes. Message me for more info.
FAQs on event logs for process mining
My IT team says that our system generates logs with timestamps. Is that not enough for process mining?
This is a good starting point. However, you will still need to clean this data. Specifically, the system data might be recorded at too granular a level. You need to ensure system activities are grouped at a level of abstraction that is consistent with the process activity you are trying to capture.
Put differently, it is unlikely that generic system logs capture exactly how your particular business carries out your particular process.
In addition, you should add business data to the logs so your analysis generates the most valuable insights (information such as resource type, costs, location, etc.)
The process mining tool I’m looking at has system connectors that will sort event logs for me. Isn’t this just a technical issue that I can leave to technical people?
It’s true that the leading process mining solutions have libraries of connectors that can import your data and create live connections. However, if you are just starting out with process mining I would strongly recommend that you slow down and create your own event log directly from your systems to start with, independent of the process mining tool.
This is because the event log is so crucial to the process mining analysis that you should have as much confidence as you possibly can in how you convert system data into the event log. The way you build confidence – and can therefore explain the data to your business stakeholders – is to create the event log yourself in the first instance.
Once you have established organisational trust and confidence in how your system data is being converted into an event log, then by all means ‘operationalise’ your data model and leverage vendor-based live connectors.
How difficult is it to create event logs? I’m not a coder but I want to start doing process mining.
The actual coding knowledge required to create event logs from system data is not hugely complicated. Very basic knowledge of SQL and Python is sufficient (see the resources section above for my learning recommendations). You should be familiar with basic data wrangling techniques (cleaning, grouping, joining tables, etc.).
If you use a low-code analytics workbench solution like KNIME, creating event logs can become even less of a technical challenge. This has the added benefit of making your data model more accessible to other stakeholder groups as you build your organisation’s process mining capability.
I don’t think I can emphasise enough the importance of getting confidence in your process data as you start a process mining capability. You *will* get push back from people once you start making recommendations via process mining. So whether you are technical or not, you must be able to defend how you created your event log if you want to see process mining succeed in your organisation.
Leave a Reply
Want to join the discussion?Feel free to contribute!